
Abstract
We tackle the task of conditional music generation. We introduce MusicGen, a single Language Model (LM) that operates over several streams of compressed discrete music representation, i.e., tokens. Unlike prior work, MusicGen is comprised of a single-stage transformer LM together with efficient token interleaving patterns, which eliminates the need for cascading several models, e.g., hierarchically or upsampling. Following this approach, we demonstrate how MusicGen can generate high-quality samples, while being conditioned on textual description or melodic features, allowing better controls over the generated output. We conduct extensive empirical evaluation, considering both automatic and human studies, showing the proposed approach is superior to the evaluated baselines on a standard text-to-music benchmark. Through ablation studies, we shed light over the importance of each of the components comprising MusicGen. Music samples, code, and models are available at https://github.com/facebookresearch/audiocraft.
1 Introduction
Text-to-music is the task of generating musical pieces given text descriptions, e.g., “90s rock song with a guitar riff”. Generating music is a challenging task as it requires modeling long range sequences. Unlike speech, music requires the use of the full frequency spectrum [Müller, 2015]. That means sampling the signal at a higher rate, i.e., the standard sampling rates of music recordings are 44.1 kHz or 48 kHz vs. 16 kHz for speech. Moreover, music contains harmonies and melodies from different instruments, which create complex structures. Human listeners are highly sensitive to disharmony [Fedorenko et al., 2012, Norman-Haignere et al., 2019], hence generating music does not leave a lot of room for making melodic errors. Lastly, the ability to control the generation process in a diverse set of methods, e.g., key, instruments, melody, genre, etc. is essential for music creators.
Recent advances in self-supervised audio representation learning [Balestriero et al., 2023], sequential modeling [Touvron et al., 2023], and audio synthesis [Tan et al., 2021] provide the conditions to develop such models. To make audio modeling more tractable, recent studies proposed representing audio signals as multiple streams of discrete tokens representing the same signal [Défossez et al., 2022]. This allows both high-quality audio generation and effective audio modeling. However, this comes at the cost of jointly modeling several parallel dependent streams.
Kharitonov et al. [2022], Kreuk et al. [2022] proposed modeling multi-streams of speech tokens in parallel following a delay approach, i.e., introduce offsets between the different streams. Agostinelli et al. [2023] proposed representing musical segments using multiple sequences of discrete tokens at different granularity and model them using a hierarchy of autoregressive models. In parallel, Donahue et al. [2023] follows a similar approach but for the task of singing to accompaniment generation. Recently, Wang et al. [2023] proposed tackling this problem in two stages: (i) modeling the first stream of tokens only; (ii) then, apply a post-network to jointly model the rest of the streams in a non-autoregressive manner.
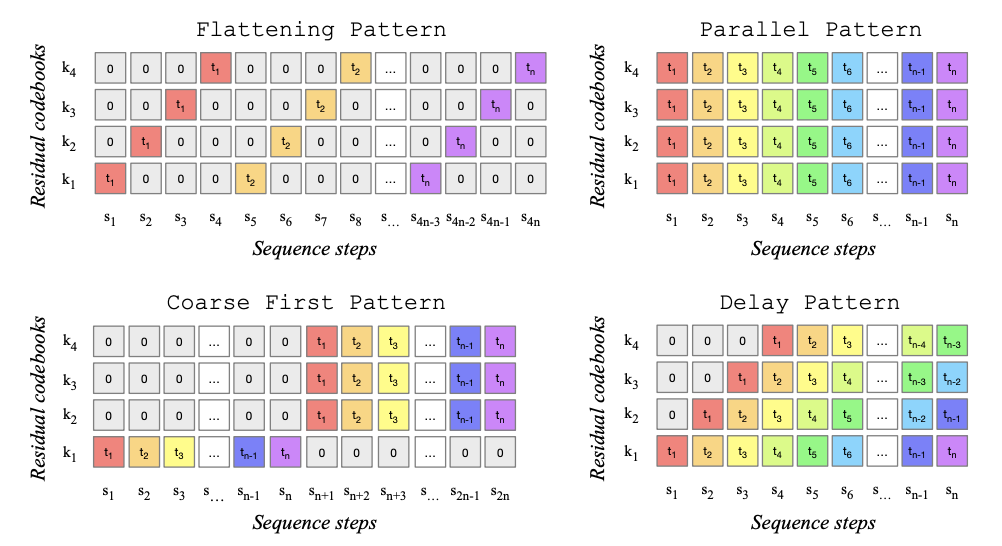
Figure 1: Codebook interleaving patterns presented in Section 2.2. Each time step t1, t2, . . . , tn is composed of 4 quantized values (corresponding to k1, . . . , k4). When doing autoregressive modelling, we can flatten or interleave them in various ways, resulting in a new sequence with 4 parallel streams and steps s1, s2, . . . , sm. The total number of sequence steps S depends on the pattern and original number of steps T. 0 is a special token indicating empty positions in the pattern.
In this work, we introduce MUSICGEN, a simple and controllable music generation model, which is able to generate high-quality music given textual description. We propose a general framework for modeling multiple parallel streams of acoustic tokens, which serves as a generalization of previous studies (see Figure 1). We show how this framework allows to extend generation to stereo audio at no extra computational cost. To improve controllability of the generated samples, we additionally introduce unsupervised melody conditioning, which allows the model to generate music that matches a given harmonic and melodic structure. We conduct an extensive evaluation of MUSICGEN and show the proposed method is superior to the evaluated baselines by a large margin, with a subjective rating of 84.8 out of 100 for MUSICGEN against 80.5 for the best baseline. We additionally provide an ablation study which sheds light on the importance of each of the components on the overall model performance. Lastly, human evaluation suggests that MUSICGEN yields high quality samples which are better melodically aligned with a given harmonic structure, while adhering to a textual description.
Our contribution:
- (i) We introduce a simple and efficient model to generate high quality music at 32 kHz. We show that MUSICGEN can generate consistent music with a single-stage language model through an efficient codebook interleaving strategy.
- (ii) We present a single model to perform both text and melody-conditioned generation and demonstrate that the generated audio is coherent with the provided melody and faithful to the text conditioning information.
- (iii) We provide extensive objective and human evaluations on the key design choices behind our method.
2 Method
MUSICGEN consists in an autoregressive transformer-based decoder [Vaswani et al., 2017], conditioned on a text or melody representation. The (language) model is over the quantized units from an EnCodec [Défossez et al., 2022] audio tokenizer, which provides high fidelity reconstruction from a low frame rate discrete representation. Compression models such as [Défossez et al., 2022, Zeghidour et al., 2021] employ Residual Vector Quantization (RVQ) which results in several parallel streams. Under this setting, each stream is comprised of discrete tokens originating from different learned codebooks. Prior work, proposed several modeling strategies to handle this issue [Kharitonov et al., 2022, Agostinelli et al., 2023, Wang et al., 2023]. In this work, we introduce a novel modeling framework, which generalizes to various codebook interleaving patterns, and we explore several variants. Through patterns, we can leverage the internal structure of the quantized audio tokens. Finally, MUSICGEN supports conditional generation based on either text or melody.
2.1 Audio tokenization
We use EnCodec, a convolutional auto-encoder with a latent space quantized using Residual Vector Quantization, and an adversarial reconstruction loss. thus quantized values for different codebooks are in general not independent, and the first codebook is the most important one.
2.2 Codebook interleaving patterns (see Figure 1)
Exact flattened autoregressive decomposition. An autoregressive model requires a discrete random sequence U S with S the sequence length. By convention, we will take U0 = 0, a deterministic special token indicating the beginning of the sequence. We can then model the distribution

6 Discussion
We introduced MUSICGEN, a state-of-the-art single stage controllable music generation model that can be conditioned on text and melody. We demonstrated that simple codebook interleaving strategies can be used to achieve high quality generation, even in stereo, while reducing the number of autoregressive time steps compared to the flattening approach. We provided a comprehensive study of the impact of model sizes, conditioning methods, and text pre-processing techniques. We also introduced a simple chromagram-based conditioning for controlling the melody of the generated audio.
Limitations Our simple generation method does not allow us to have fine-grained control over adherence of the generation to the conditioning, we rely mostly on CF guidance. Also, while it is relatively straightforward to do data augmentation for text conditioning, conditioning on audio warrants further research on data augmentation, types and amount of guidance.
Broader impact. Large scale generative models present ethical challenges. We first ensured that all the data we trained on was covered by legal agreements with the right holders, in particular through an agreement with ShutterStock. A second aspect is the potential lack of diversity in the dataset we used, which contains a larger proportion of western-style music. However, we believe the simplification we operate in this work, e.g., using a single stage language model and a reduced number of auto-regressive steps, can help broaden the applications to new datasets. Generative models can represent an unfair competition for artists, which is an open problem. Open research can ensure that all actors have equal access to these models. Through the development of more advanced controls, such as the melody conditioning we introduced, we hope that such models can become useful both to music amateurs and professionals.
Ethical statement. This paper is finalized in the wake of a tragic terrorist attack perpetrated by Hamas, which has left the Israeli nation profoundly devastated. On Oct. 7, 2023, thousands of Hamas terrorists infiltrated the Israeli border, launching a ferocious assault on 22 Israeli villages, brutally murdering more than a thousand innocent lives, and kidnapping more than two hundred civilians.
While we grieve and mourn our friends and family, we call all the academic community to unite in condemnation of these unspeakable atrocities committed by Hamas, and to advocate for the prompt and safe return of the abductees, as we stand together in the pursuit of peace.
In memory of the countless lives shattered by the Hamas actions.